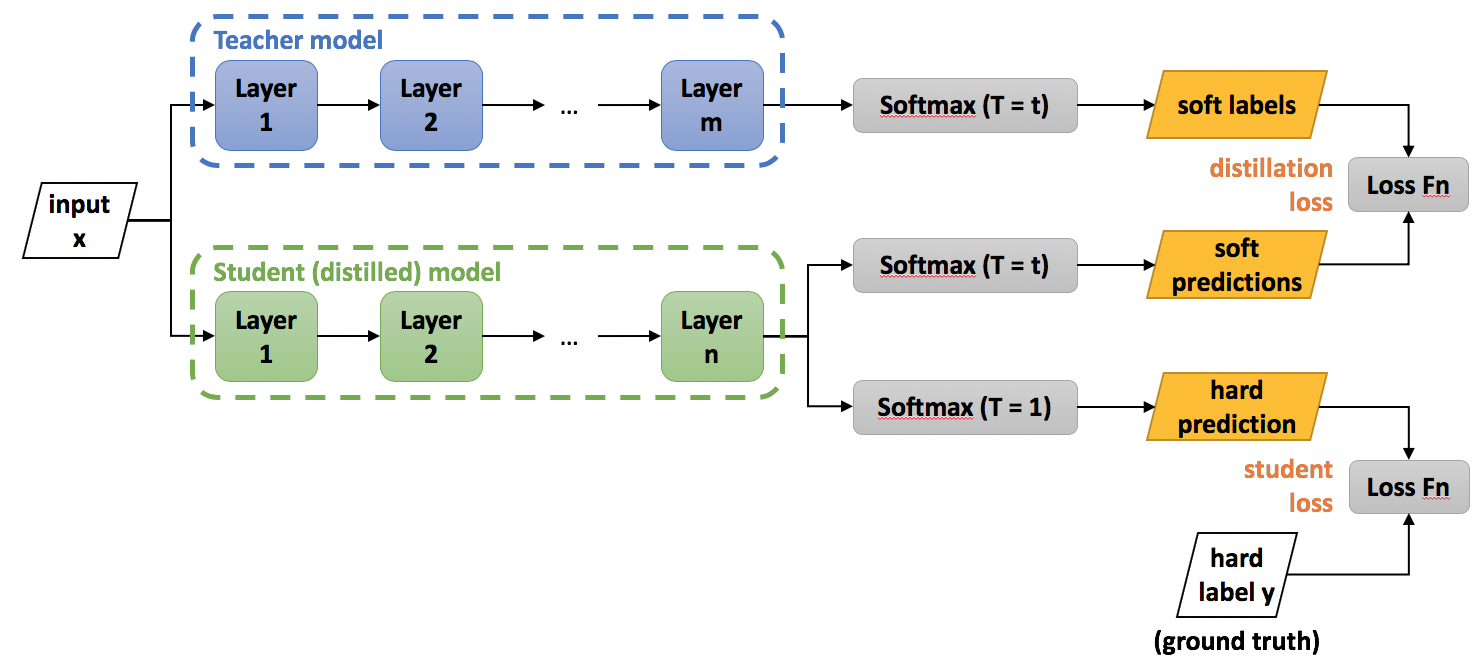
Knowledge Distillation (KD) là một kỹ thuật nén model (model compression) sao cho độ chính xác (hoặc một thước đo khác như mAP, và F1-score, ...) không thay đổi nhiều so với model gốc.
Bài toán thực tế
Nén model phân loại chữ viết tay sử dụng kỹ thuật KD, với bộ dữ liệu MNIST
Bước 1: Import các thư viện cần thiết
1 2 3 4 5 6 7 8 9 10
import torch from torchvision.datasets import MNIST import torchvision.transforms as transforms import torch.nn as nn import torch.nn.functional as F import torch.optim as optim
import numpy as np from numpy import vstack from sklearn.metrics import accuracy_score
Bước 2: Load dữ liệu
Ở bước này chúng ta sẽ load bộ dữ liệu MNIST,và biến đổi dữ liệu sao cho model có thể sử dụng được. Lưu ý rằng bộ dữ liệu này có sẵn trong thư viện torchvision rồi, nên chỉ cần load lên mà không cần vào trang chủ của bộ dữ liệu để tải nha.
1 2 3 4 5 6 7 8 9 10 11 12 13
# định nghĩa phép chuyển đổi: thay đổi kích thước ảnh thành 32x32, và chuyển đổi # dữ liệu sang dạng tensor transform = transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor(), ]) # load tập dữ liệu train và test, và áp dụng phép chuyển đổi cho tập dữ liệu train_set = MNIST(root='tmp/', train=True, download=True, transform=transform) test_set = MNIST(root='tmp/', train=False, download=True, transform=transform)
# tạo loader để truyền vào model dữ liệu theo batch train_loader = torch.utils.data.DataLoader(train_set, batch_size=128, shuffle=True) test_loader = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)
Bước 3: Xây dựng các model
Chúng ta sẽ xây dựng 2 model ở bước này:
Model giáo viên (teacher): model gốc (LeNet5)
Model học sinh (student): model sau khi nén bằng cách giữ nguyên số lượng layer, nhưng giảm số lượng tham số (parameters)
defforward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
defnum_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features
defforward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), 2) x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
defnum_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features
Bước 3: Train các model
Model giáo viên
Đầu tiên chúng ta sẽ định nghĩa hàm loss và optimizer cho model như sau:
for epoch inrange(100): running_loss = 0.0 for i, data inenumerate(train_loader, start=0): # get the inputs; data is a list of [inputs, labels] inputs, labels = data
for epoch inrange(50): running_loss = 0.0 for i, data inenumerate(train_loader, start=0): # get the inputs; data is a list of [inputs, labels] inputs, labels = data
model học sinh sử dụng thêm 1 loại loss nữa, đó là $distillation\ loss$, được tính bằng KL divergence giữa phân phối của model giáo viên và model học sinh.
Tham số $alpha$ dùng để đánh trọng số (weight) cho $student\ loss$ và $distillation\ loss$.
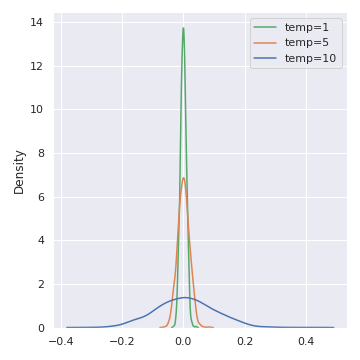
Tham số $temperature$ có tác dụng làm phân phối “soft” hơn. Tham số này càng tăng, thì phân phối càng “soft”, như hình dưới đây:
Tại sao không train model học sinh từ đầu?
Chúng ta hoàn toàn có thể train model học sinh từ đầu, tuy nhiên sẽ khó đạt được kết quả như kỳ vọng. Kỹ thuật KD giúp model học sinh:
Generalize tốt hơn, do tập train của model giáo viên thông thường sẽ lớn hơn nhiều so với tập train của model học sinh
$distillation\ loss$ giảm thiểu ảnh hưởng của việc phân bố tập train của model học sinh khác nhiều so với phân bố thực tế