

Có nhiều hình thức để serve một model, và cũng có nhiều tool/framework hỗ trợ chúng ta làm điều này.
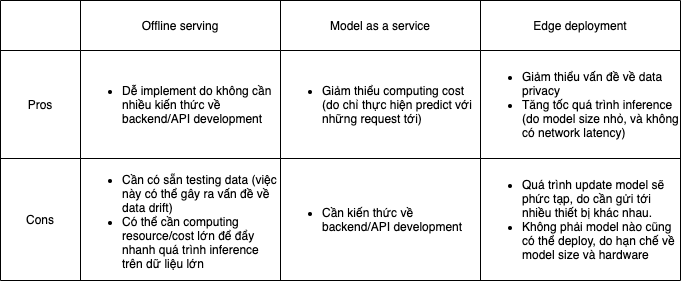
1. Các hình thức serving
- Offline serving (batch inference): model dự đoán trên cả tập dữ liệu test, và lưu kết quả vào 1 database hoặc storage.
- Model as a service: đóng gói model thành một service và cung cấp API endpoint cho user. User sẽ tạo POST/GET request tới endpoint này để trigger quá trình model inference và nhận về kết quả.
- Edge deployment: chuyển đổi model thành định dạng phù hợp (ví dụ ONNX) để deploy trên các thiết bị edge (ví dụ: browser, Raspberry Pi, Nvidia Jetson Nano, và Google Coral, …)
2. Khi nào thì dùng hình thức serving nào
3. BentoML
BentoML là một framework hỗ trợ đóng gói và deploy model trên nhiều nền tảng khác nhau, ví dụ:
- Serverless Compute Services như AWS Lambda và Google Cloud Run
- Compute Engine như Amazon EC2
- AI Platform như Amazon SageMaker, VertexAI
- Kubernetes Cluster như Kubeflow
Bên cạnh đó BentoML cũng cung cấp CLI, Python API và Web UI để quản lý các model trên production.
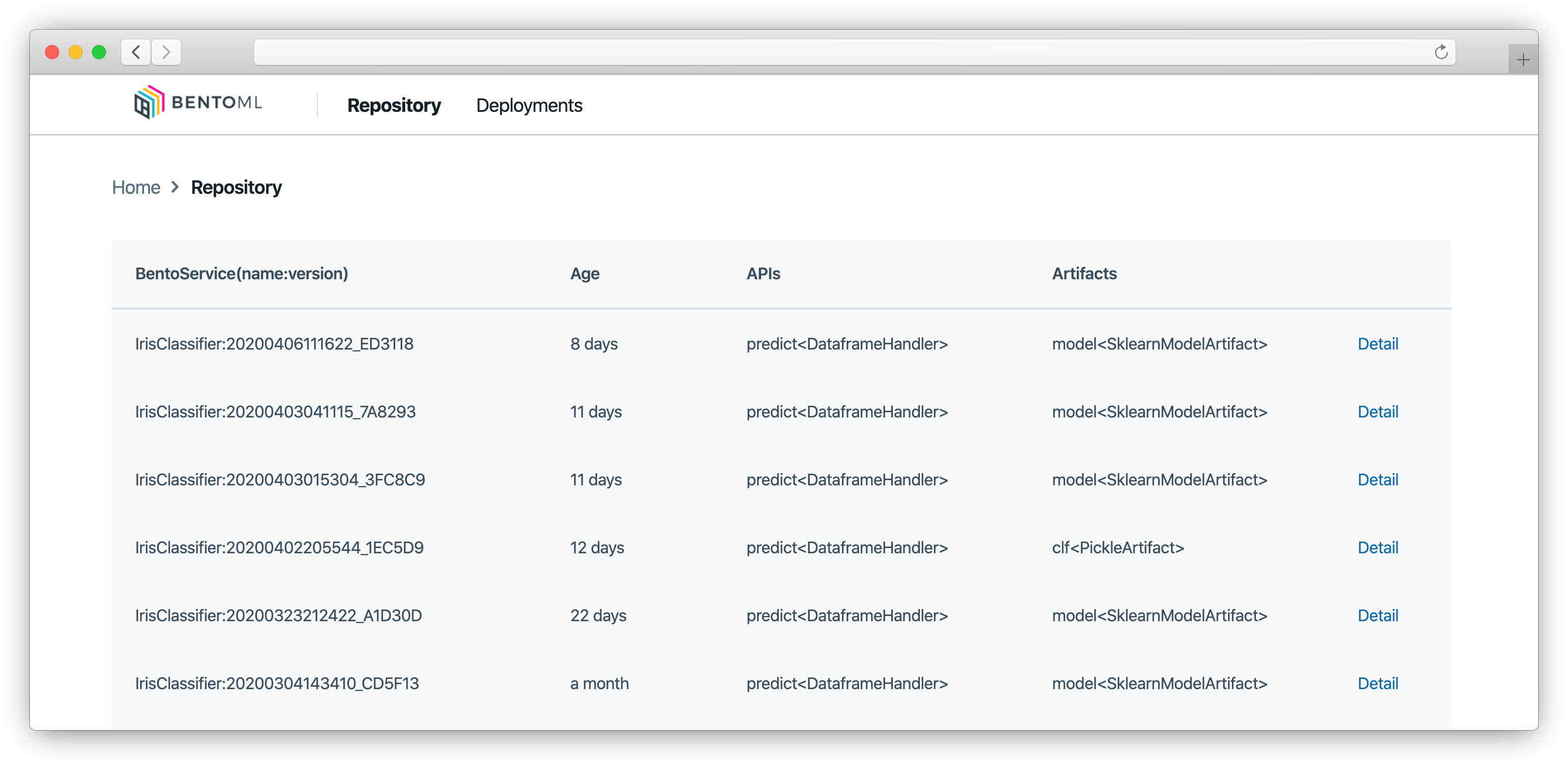
4. Quickstart
Cài đặt BentoML khá đơn giản, chỉ cần chạy command
1 | pip install bentoml==0.13.1 |
Quickstart này sẽ hướng dẫn mọi người cách serve một model SVM đơn giản (train trên dữ liệu Iris) dưới hình thức Model as a service.
Project structure của chúng ta sẽ như sau:
1 | bentoml-tutorials/ |
File bento_service.py dùng để định nghĩa BentoService, bao gồm thông tin về model, package dependencies và code để predict
1 | import pandas as pd |
Ở Line 10, bằng cách khai báo InputAdapter là DataFrameInput, BentoML sẽ chuyển input cho API sang dạng DataFrame trước khi truyền vào hàm predict. Framework này cũng hỗ trợ một số loại InputAdapter khác để đối ứng với các loại dữ liệu khác nhau, ví dụ như: JsonInput, ImageInput, và TfTensorInput, … (xem thêm tại đây. Khi sử dụng batch=True, chế độ Adaptive Micro Batching sẽ được kích hoạt, cho phép chờ và xử lý nhiều request một lúc thay vì từng request một.
File train.py sẽ dùng để training model, và đóng gói model thành 1 BentoService bundle
1 | from bento_service import IrisClassifier |
Sau khi run file này thì các bác sẽ thấy log ở console tương tự như sau:
1 | BentoService bundle 'IrisClassifier:0.0.1' saved to: /Users/yourusername/bentoml/repository/IrisClassifier/0.0.1 |
Dưới đây là cấu trúc thư mục của BentoService bundle. Mọi người có thể thấy đoạn code snippet của chúng ta đã được bundle thành rất nhiều file khác để sẵn sàng cho việc đóng gói và deploy mà không cần quá nhiều kiến thức về Docker hay DevOps.
1 | . |
Bây giờ để start API server chúng ta chỉ cần sử dụng đường dẫn tới bundle vừa nãy như sau:
1 | $ bentoml serve /Users/yourusername/bentoml/repository/IrisClassifier/0.0.1 --port 5005 |
và sẽ thấy ứng dụng đang run ở port 5005
1 | $ bentoml serve /Users/quandv6/bentoml/repository/IrisClassifier/0.0.1 --port 5005 |
Thử tạo một request tới API thôi nào!
1 | $ curl -i \ |
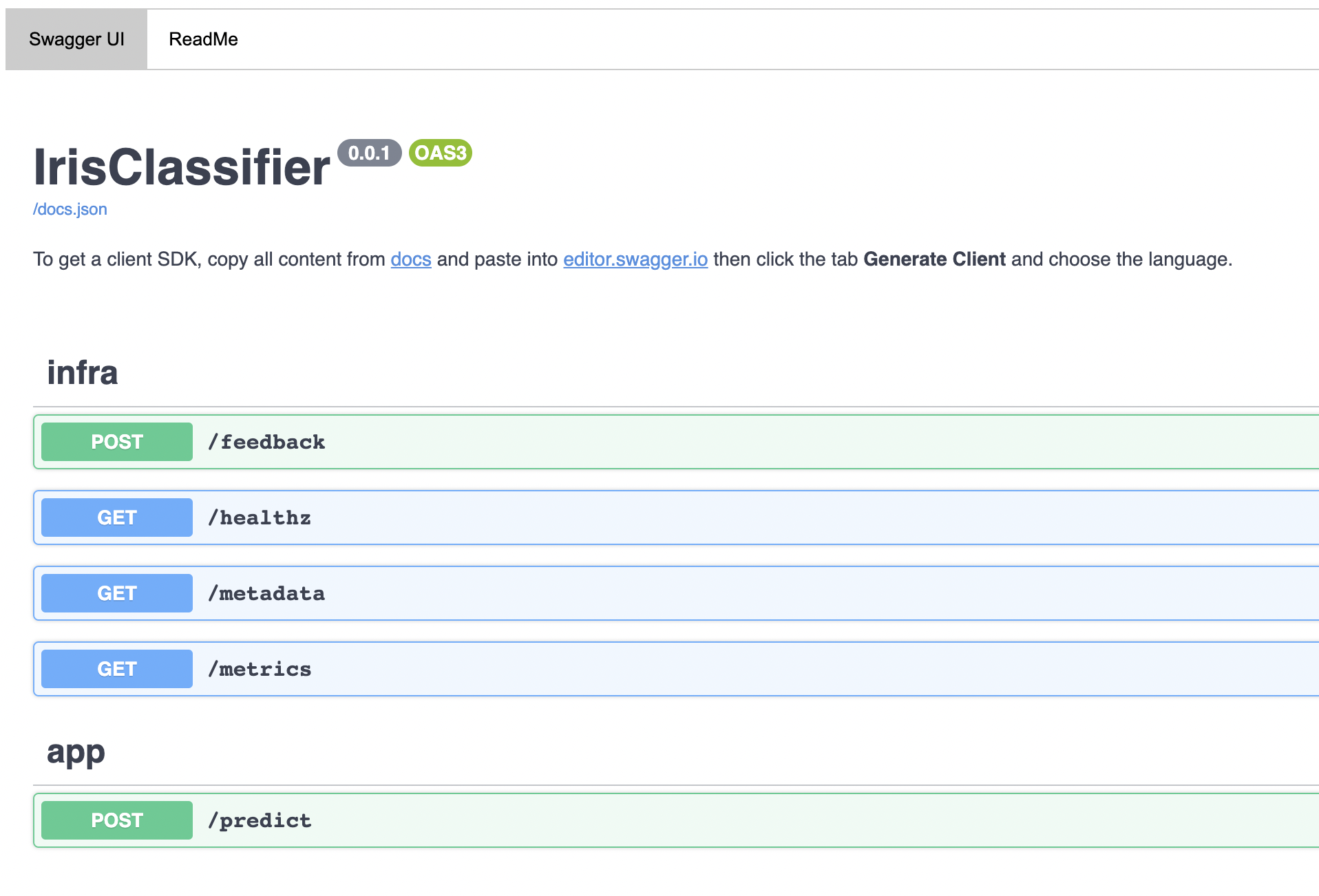
Nếu chúng ta truy cập vào đường dẫn http://localhost:5005/ sẽ thấy Swagger UI, chính là document cho các endpoints hiện tại.
Bây giờ hãy start yatai và vào http://localhost:5006 để xem thông tin của các model nào
1 | $ bentoml yatai-service-start --ui-port 5006 --grpc-port 5007 |
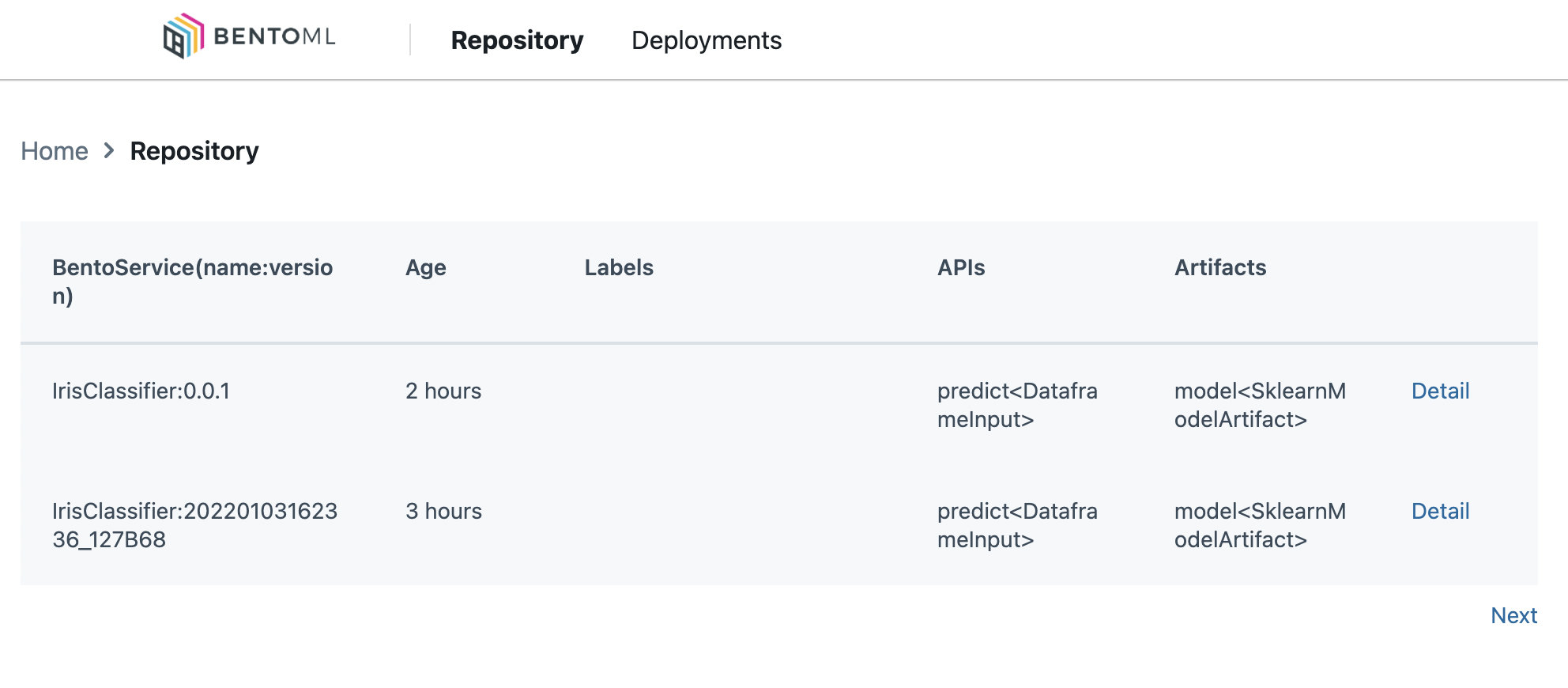
OK! Thế là chúng ta đã có một model được serve theo hình thức Model as a service, và một model management UI để quản lý các version của model. Triển khai Offline serving với BentoML khá đơn giản với command như sau, với argument là file đầu vào định dạng CSV.
1 | bentoml run IrisClassifier:0.0.1 predict --format csv --input-file test_data/test-offline-batch.csv |
Bản chất của command này là sẽ biến input file CSV thành định dạng DataFrame, và sau đó đưa qua hàm predict định nghĩa trong BentoService IrisClassifier. Các bác tham khảo thêm tại đây
5. Một số lưu ý
5.1. Adaptive Micro Batching
2 tham số quan trọng cần chú ý khi sử dụng Adaptive Micro Batching:
- mb_max_batch_size: kích thước tối đa của 1 batch
- mb_max_latency: thời gian phàn hồi tối đa (đơn vị miliseconds)
Dựa vào 2 tham số trên, framework sẽ tự điều chỉnh thời gian chờ và kích thước batch sao cho throughput (số lượng request xử lý trong một lần) là lớn nhất và latency (thời gian phản hồi) là nhỏ nhất. Nếu các bác quan tâm về cơ chế tự điều chỉnh này, có thể xem thêm tại đây.
5.2. Monitoring với Prometheus
Sau khi đã start API server, chúng ta có thể lấy một số metrics có sẵn thông qua /metrics endpoint như sau:
1 | curl http://localhost:5005/metrics |
Các bác có thể thêm các metrics khác, ví dụ như request_processing_time như sau
1 | from prometheus_client import Summary |
5.3. Metadata
Endpoint /metadata được tạo ra tự động để cung cấp thông tin về model deployment, bao gồm một số trường như tên, ngày tạo, và dependencies, …
1 | curl http://localhost:5005/metadata |
Ngoài ra, chúng ta hoàn toàn có thể thêm các thông tin khác ngoài những thứ có sẵn như sau
1 | iris_classifier_service.pack( |
6. Nhận xét
BentoML là một framework giúp chúng ta có thể deploy một model dễ dàng và nhanh chóng mà không cần quá nhiều kiến thức về Software Developement và DevOps. Sử dụng BentoML cũng giúp linh hoạt trong việc deploy trên các platform khác nhau, cũng như chuyển giao giữa các platform. Tuy nhiên, framework này cũng có nhược điểm đó là chỉ hỗ trợ đóng gói model, mà không thể tự handle horizontal hay auto-scaling. Muốn khắc phục vấn đề này thì phải kết hợp BentoML với một orchestration framework như Kubernetes hoặc Seldon (chúng ta sẽ tìm hiểu trong các bài sau).
Code về tutorial các bác có thể xem ở đây: https://github.com/quan-dang/bentoml-tutorials