
Hello cả nhà =)) sau bao nhiêu ngày ở ẩn, mình đã quyết định trở lại với phần 2 của model serving sử dụng Seldon Core. Phần này sẽ có những chủ đề sau:
- Autoscale model serving với KEDA
- Customize metrics cho Prometheus
- REST Health endpoint
Prerequisites
1. Horizontal Pod Autoscaler (HPA)
HPA object trong Kubernetes (k8s) được sử dụng để tự động tăng/giảm số lượng pod trong 1 deployment, replica set, hoặc statefulset dựa trên các metrics được định nghĩa sẵn trong manifest bao gồm CPU/memory utilization, hoặc một custom metric khác. Loại scale này gọi là horizontal scale, còn tăng cấu hình CPU, memory, storage, .v.v. thì gọi là vertical scale.
Dưới đây là ví dụ về một HPA manifest:
1 | apiVersion: autoscaling/v1 |
HPA trên sẽ tự động thay đổi số lượng pod cho deployment hello-world dựa trên mean CPU utilization percentage của tất cả các pod. HPA cũng đảm bảo số lượng pod tối thiếu là 1, và tối đa là 10. Về cơ chế scale của HPA, mọi người xem thêm tại đây
2. KEDA
KEDA (Kubernetes-based Event Driven Autoscaler) mở rộng HPA, cho phép scale workload thông qua external metrics, ví dụ metrics từ Prometheus query.
KEDA có 3 thành phần chính:
- Scaler: kết nối với external source và fetch metrics
- Controller: scale pod từ/xuống 0 và tạo HPA
- Metrics Adapter: biên dịch external metrics sang dạng HPA có thể hiểu được, mình cảm thấy đây là một chức năng khá quan trọng, cho phép người dùng không cần tự viết custom metrics phức tạp trực tiếp trên HPA
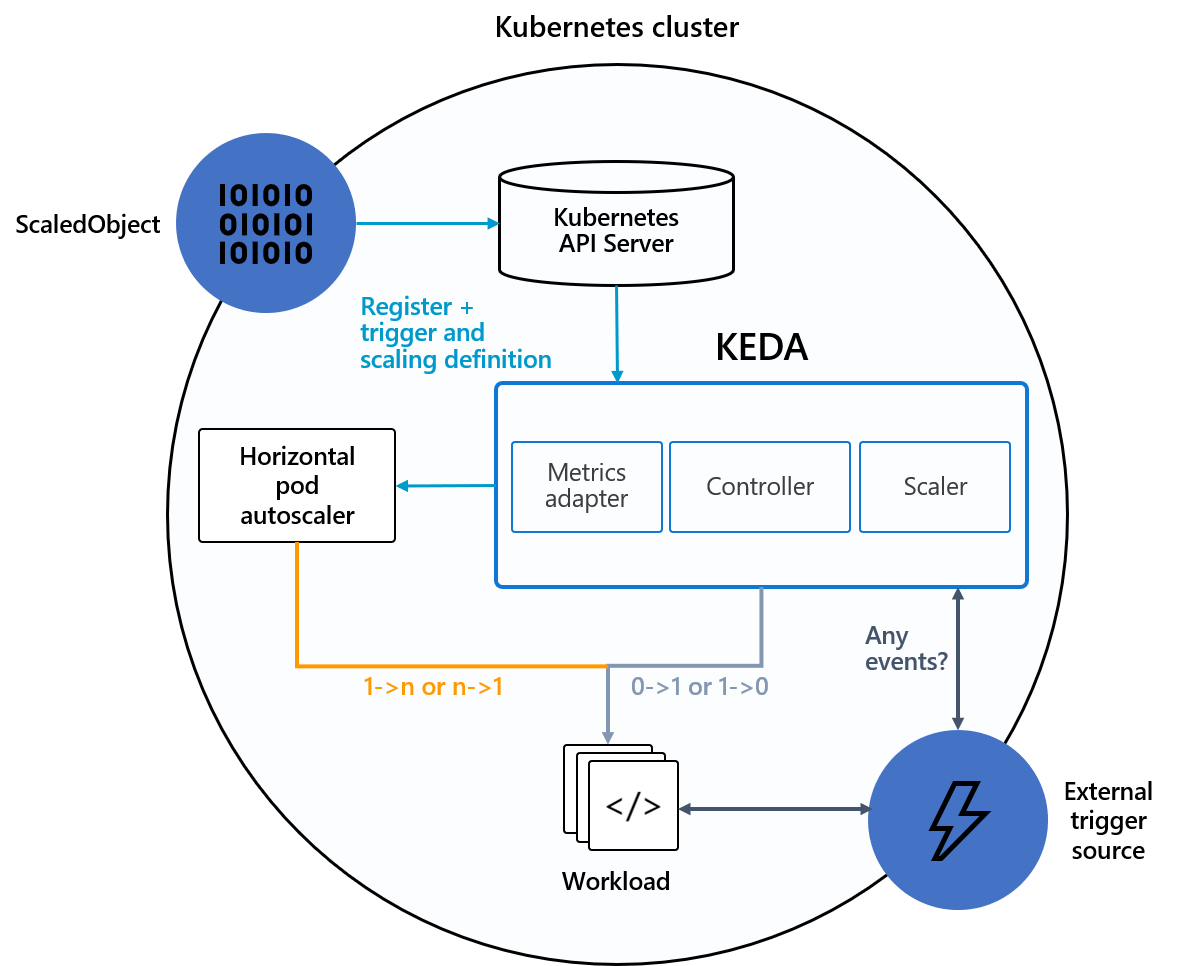
I. Horizontal scale model deployment với KEDA
1. Cài đặt KEDA
Cài đặt KEDA khá đơn giản chỉ với một vài command như sau:
1 | helm repo add kedacore https://kedacore.github.io/charts |
Để sử dụng KEDA với Seldon Core thì mọi người thêm flag --set keda.enabled=true lúc cài đặt
1 | helm install seldon-core seldon-core-operator \ |
2. Sử dụng KEDA
Sử dụng KEDA để autoscale các Seldon deployments khá đơn giản, chỉ cần thêm kedaSpec để mô tả cách mà mọi người muốn scale
1 | # seldon.yaml |
Sau khi apply manifest trên, seldon-controller-manager sẽ khởi tạo 1 object Seldon Deployment. Object này sẽ tạo 1 ScaledObject tương đương với cấu hình scale được định nghĩa trong kedaSpec: số pod tối thiếu là 1 và tối đa là 3, thực hiện query prometheus-server 15s một lần, và threshold để quyết định scale là 10.
II. Customize metrics cho Prometheus
Bên cạnh default metrics expose bởi service orchestrator (executor), ví dụ seldon_api_executor_client_requests_seconds_count ở trên, chúng ta hoàn toàn có thể thêm custom metrics bằng cách thêm 1 method metrics như sau:
1 | class ModelWithMetrics(object): |
III. REST health endpoint
Health checks hay probes được sử dụng bởi kubelet để xác định khi nào restart 1 container (liveness probe), sử dụng bởi các services và deployments để xác định pod đã sẵn sàng nhận traffic chưa.
Chúng ta có thể implement method health_status như sau:
1 | class ModelWithHealthEndpoint(object): |
Và ghi đè cấu hình default liveness/readiness probes mặc định:
1 | kind: SeldonDeployment |
Chúng ta cũng có thể tự xác định xem model vừa deploy có chạy ngon lành không bằng cách gọi tới route /health/status hoặc /health/ping.
References
[1] https://cloud.redhat.com/blog/kubernetes-autoscaling-3-common-methods-explained
[2] https://cloudblogs.microsoft.com/opensource/2020/05/12/scaling-kubernetes-keda-intro-kubernetes-based-event-driven-autoscaling/
[3] https://viblo.asia/p/kubernetes-practice-kubernetes-based-event-driven-autoscaler-3Q75wAG9ZWb
[4] https://kubebyexample.com/en/concept/health-checks